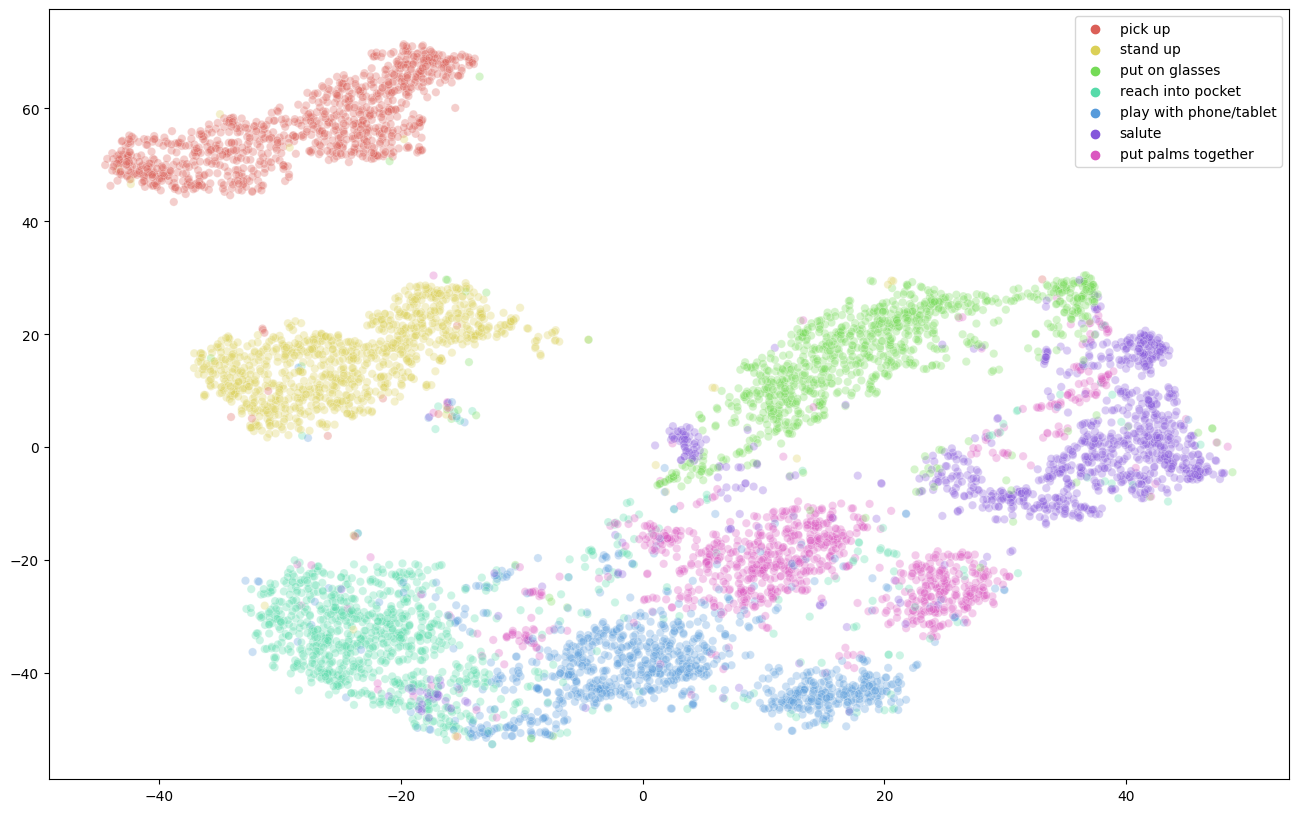
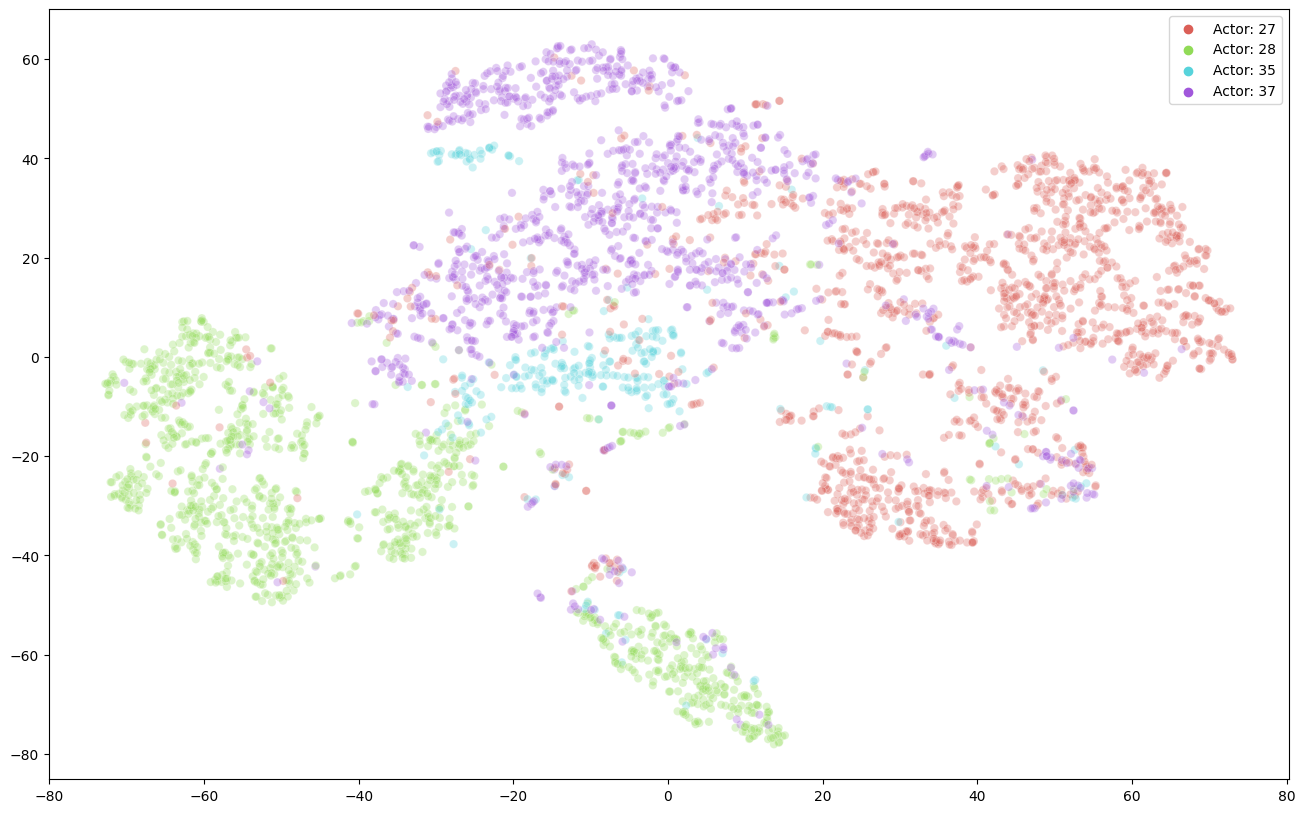
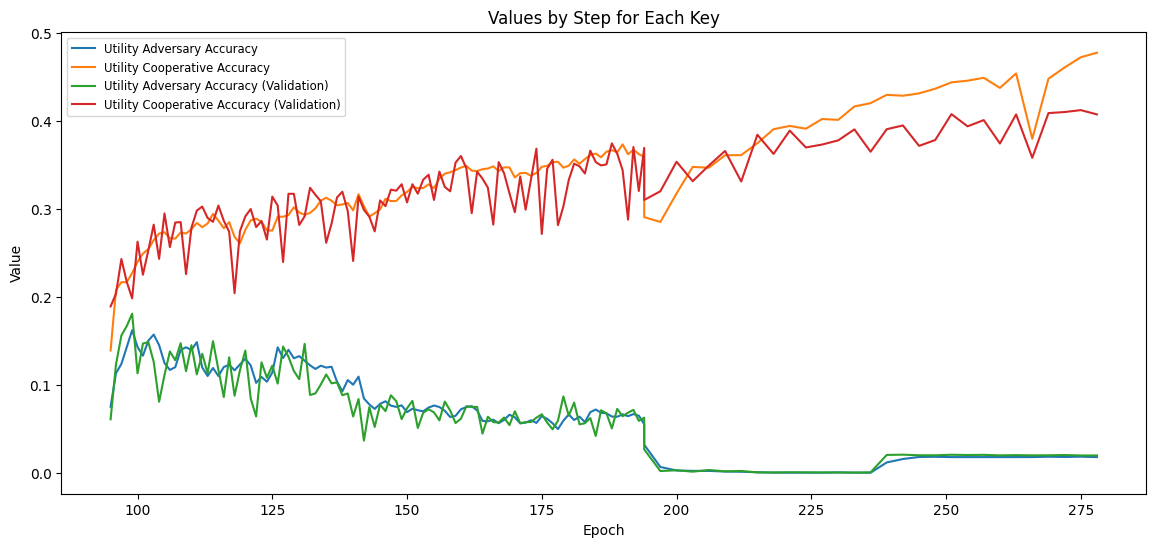
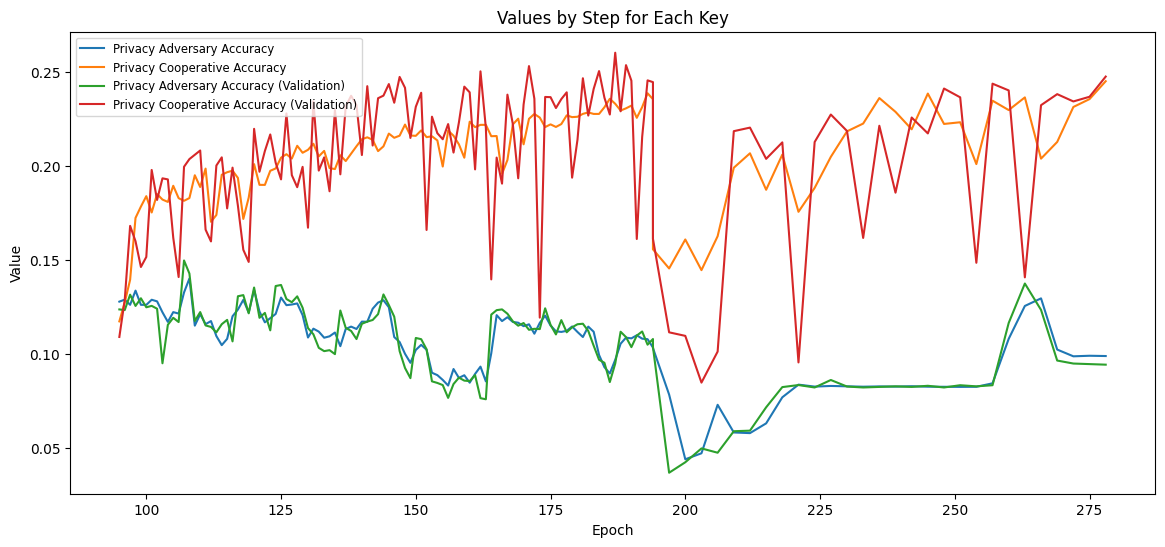
Performance Comparison on NTU RGB+D 60
| Method | MSE ↓ | AR Top-1 ↑ | AR Top-5 ↑ | Re-ID Top-1 ↓ | Re-ID Top-5 ↓ | Gender ↓ | Linkage ↓ |
|---|---|---|---|---|---|---|---|
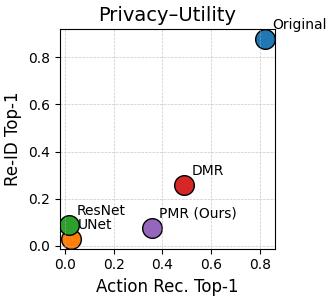
| Original | - | 82.2% | 85.0% | 87.8% | 97.3% | 88.7% | 69.6% |
| UNet (Moon et al.) | 0.0834 | 2.6% | 11.1% | 3.0% | 26.8% | 3.0% | 50.0% |
| ResNet (Moon et al.) | 0.2988 | 1.8% | 11.2% | 9.1% | 34.1% | 9.0% | 50.8% |
| DMR (Baseline) | 0.0071 | 49.1% | 73.1% | 25.7% | 60.3% | 25.7% | 50.0% |
| PMR (Ours) | 0.0138 | 35.7% | 63.0% | 7.8% | 26.4% | 7.8% | 50.0% |
Key Findings
Optimal Privacy-Utility Trade-off
PMR achieves the best balance between privacy protection (7.8% Top-1 re-ID) and utility preservation (35.7% Top-1 action recognition).
Superior to Baselines
Outperforms UNet by 13.7× in action recognition (35.7% vs 2.6%) while maintaining strong privacy protection.
Strong Privacy Guarantees
Reduces re-identification from 87.8% to 7.8% (Top-1) and linkage attacks to random chance (50.0%).
Low Reconstruction Error
MSE of 0.0138 ensures visually plausible skeletons while anonymizing identity, balancing between DMR (0.0071) and Moon's methods (0.0834+).